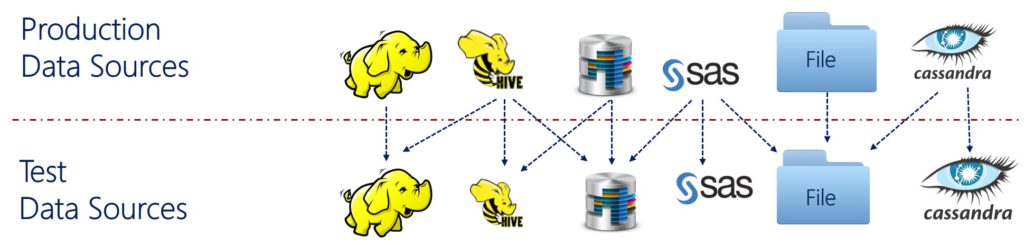
Pricchaa provides software solutions to detect and encrypt sensitive data elements within testing data sources. More specifically, Pricchaa enables you to:
- Identify sensitive data elements automatically or user configuration mode
- Encrypt sensitive data elements while preserving format and referential integrity between all source systems
- Maintain referential integrity throughout the life cycle of the project including incremental test data
- Decrypt test results for validation
Supported Data Sources
| Source Type | Supported Sources |
|---|---|
| Big Data Platform | Apache Hadoop, Cloudera, Hortonworks, MapR |
| No SQL Databases | MarkLogic, MongoDB, Cassandra, Hbase, Hive |
| Cloud Sources | S3, AWS Redshift, Snowflake |
| Regular Databases | Oracle, MS-SQL, Vertica, Teradata |
| File System | Linux, Windows, SAS Files |
Why Pricchaa ?
Our Advantages
Advanced Encryption Technology
We have implemented advanced Format Preserving Encryption using FE1 scheme. We also used Key Management Interoperability Protocol(KMIP) to store the encryption keys securely
Adaptive Machine Learning Algorithm
Our solution leverages big data deep learning algorithms to detect sensitive information, data anomalies, access violations and usage anomalies.
Designed for Big Data
Designed for processing large data volume. Supports traditional data sources as well no-sql big data sources. Architected for searching unstructured data such as PDF, Social Media, Microsoft Office, EPUB, compressed files etc.
Compliance Ready
Eighteen different checks are pre-built to support PII and PHI privacy data types
Independent and Non-Intrusive
Independently and non-intrusively examines data
Cloud Ready
Seamlessly examines enterprise data present in private or public cloud
Scalable
Linearly scalable to support processing of large data volume using commodity hardware
Contact Us
Installation Requirements
Pricchaa provides both cloud and on-premise installation option. Following specifications are applicable for the On-Premise Installation
Server System Requirements
- 2 quad-/hex-/octo-core CPUs, running at least 2-2.5GHz
- 64-512 GB RAM
- 1– 2 TB Hard Drive
- 2- 4 Nodes
- 10 Gigabit Ethernet
Operating System
- Linux ( Ubuntu 12+ or Redhat 6/7 ) – 64 bit
Big Data Stack
- Hadoop 2.6 ( MapR, Cloudera, HortonWorks)
- Spark 2.0
Other Software
- Apache, PHP 5.5
- MySQL 5.7